HAKE: Human Activity Knowledge Engine
MVIG - Shanghai Jiao Tong University
Introduction
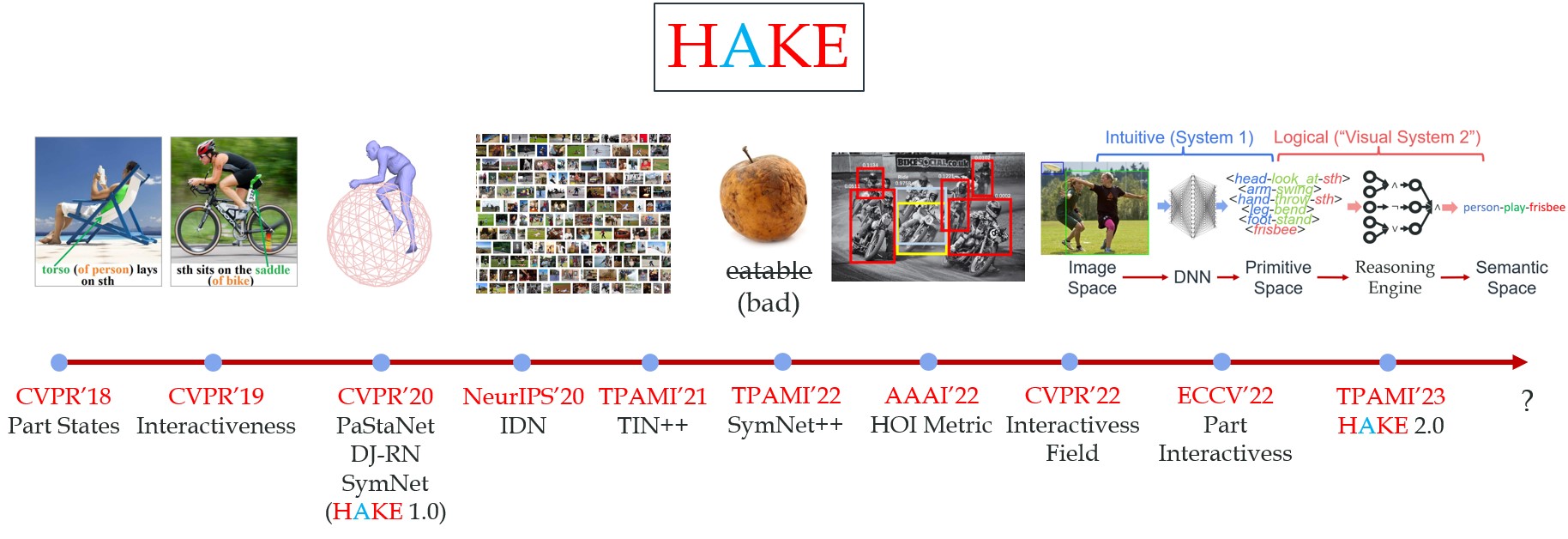
Human Activity Knowledge Engine (HAKE) is a knowledge-driven system that aims at enabling intelligent agents to perceive human activities, reason human behavior logics, learn skills from human activities, and interact with objects and environments. In detail, HAKE contains 26 M+ human body part-level atomic action labels (Part States, PaSta) and PaSta-Activity logic rules, holistic object knowledge labels (category, attribute, affordance) together with their causal relations. It boosts the performances of several widely-used human activity- and object- related benchmarks (HICO, HICO-DET, V-COCO, AVA, Ambiguous-HOI, MIT-States, UT-Zappos, aPY, SUN, etc), and can convert human boxes into multi-modal representations for diverse downstream tasks, e.g., image/video action recognition/detection, captioning, VQA, visual reasoning, etc. Now, the HAKE project contains the works from 11 papers (CVPR'18/19/20/22, NeurIPS'20, TPAMI'21/22, AAAI'22, ECCV'22). In the near future, we will release more works on object concept learning, visual reasoning, and human-robot interaction.
We will keep enriching HAKE to make it a general research platform of knowledge mining, visual reasoning, and causal inference. Come and join us!
Project
1) HAKE-Reasoning (TPAMI): Neural-Symbolic reasoning engine. HAKE-Reasoning.
2) HAKE-Image (CVPR'18/20): Human body part state (PaSta) labels in images. HAKE-HICO, HAKE-HICO-DET, HAKE-Large, Extra-40-verbs.
3) HAKE-AVA: Human body part state (PaSta) labels in videos from AVA dataset. HAKE-AVA.
4) HAKE-Action-TF, HAKE-Action-Torch, CLIP-Activity2Vec (CVPR'18/19/20/22, NeurIPS'20, TPAMI'21/22, AAAI'22, ECCV'22): SOTA action understanding methods and the corresponding HAKE-enhanced versions (TIN, IDN, IF, mPD, PartMap).
5) HAKE-3D (CVPR'20): 3D human-object representation for action understanding (DJ-RN).
6) HAKE-Object (CVPR'20, TPAMI'21): object knowledge learner to advance action understanding (SymNet).
7) HAKE-A2V (CVPR'20): Activity2Vec, a general activity feature extractor based on HAKE data, converts a human (box) to a fixed-size vector, PaSta and action scores.
8) Halpe: a joint project under Alphapose and HAKE, full-body human keypoints (body, face, hand, 136 points) of 50,000 HOI images.
9) HOI Learning List: a list of recent HOI (Human-Object Interaction) papers, code, datasets and leaderboard on widely-used benchmarks.
News
